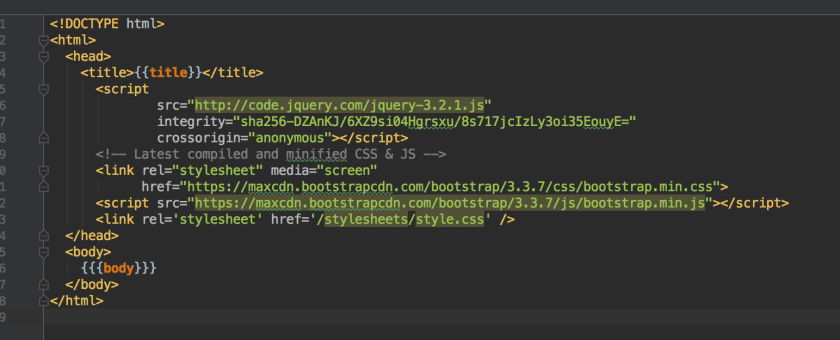
Although Spring Security provides means to secure the web tier using XML markup, it’s also critically important that developers also secure backend method to ensure that methods. This post demosntrates an application in which a developer forgot to secure a web form but luckily the backend code is secured and provides a safe guard against such an error.
Enabling JSR250
Spring Boot takes a declaritive approaching to enabling method security, but we also need to provide it with an authentication manager.
@Configuration
@EnableJpaRepositories
//The next annotation enabled @RolesAllowed annotation
@EnableGlobalMethodSecurity(jsr250Enabled = true)
//We need to extend GlobalMethodSecurityConfiguration and override the configure method
//This will allow us to secure methods
class MethodSecurityConfig : GlobalMethodSecurityConfiguration(){
override fun configure(auth: AuthenticationManagerBuilder) {
//In our case, we are going to use an in memory authentication
configureAuthentication(auth)
}
}
fun configureAuthentication(auth: AuthenticationManagerBuilder){
auth
.inMemoryAuthentication()
.withUser("bob").password("bob").roles("ADMIN", "USER")
.and()
.withUser("gene").password("gene").roles( "USER")
}
We create a class that extends GlobalMethodSecurityConfiguration. We turn the method security on by annotating this class with @EnableGlobalMethodSecurity. By default, Spring uses it’s own @Secured annotation so if we want to use the JSR standard, we need to pass true to the jsr250Enabled annotation. Then our MethodSecurityConfig class needs to override the configure method and add an authentication scheme.
Readers may be wondering what the difference is between @Secured and @RolesAllowed annotations. There doesn’t seem to be much as both annotations seem to do the same thing. There is the possibility that other software libraries may act on @RolesAllowed and if there is such as concern, then use @Secured.
Securing Methods
Once we have enabled method security, we only need to decorate our specific methods. Here is a service class used in the example application.
@Transactional
//This is our class that we are going to secure
class BurgerService(@Autowired val burgerRepository: BurgerRepository){
@PostConstruct
fun init(){
//Just popuplates the DB for the example application
val burgers = listOf(
BurgerOfTheDay(name = "New Bacon-ings"),
BurgerOfTheDay(name = "Last of the Mo-Jicama Burger"),
BurgerOfTheDay(name = "Little Swiss Bunshine Burger"),
BurgerOfTheDay(name = "Itsy Bitsy Teeny Weenie Yellow Polka-Dot Zucchini Burger"))
burgerRepository.save(burgers)
}
@PreDestroy
fun destory(){
//Clean up the DB when done
burgerRepository.deleteAll()
}
//Any user can add a new BurgerOfTheDay
@RolesAllowed(value = *arrayOf("USER", "ADMIN"))
fun saveBurger(burgerOfTheDay: BurgerOfTheDay) = burgerRepository.save(burgerOfTheDay)
//But only adminstrators get to delete burgers
@RolesAllowed(value = "ADMIN")
fun deleteBurger(id : Long) = burgerRepository.delete(id)
//Any user gets to see our Burgers
@RolesAllowed(value = *arrayOf("USER", "ADMIN"))
fun allBurgers() = burgerRepository.findAll()
}
The @RolesAllows annotation takes an array of allowed roles. In our case, we are letting anyone with the USER role to add burgers, but only ADMIN users are allowed to delete burgers. If a user without the ADMIN role attempts to invoke deleteBurger, an AccessDeniedException is thrown.
Catching Security Violations
Kotlin has no concept of checked exceptions, but Java users should note that Spring’s security exceptions are all RuntimeExceptions. If we want to report a security violation back to the user, we need to catch our security exceptions. Here is an example Controller class that handles security violations.
@Controller
class IndexController(
@Autowired val logger : Logger,
@Autowired val burgerService: BurgerService) {
@GetMapping("/")
fun doGet(model : Model) : String {
model.addAttribute("burgers", burgerService.allBurgers().toList())
return "index"
}
@PostMapping("/add")
fun saveBurger(
@RequestParam("burgerName") burgerName : String,
model : Model) : String {
try {
burgerService.saveBurger(BurgerOfTheDay(name=burgerName))
model.addAttribute("burgers", burgerService.allBurgers().toList())
model.addAttribute("info", "Burger has been added")
} catch (e : Exception){
when (e){
is AccessDeniedException -> {
logger.info("Security Exception")
}
else -> logger.error(e.toString(), e)
}
} finally {
return "index"
}
}
@PostMapping("/delete")
fun deleteBurgers(
@RequestParam("ids") ids : LongArray,
model: Model) : String {
var errorThrown = false
ids.forEach {
try {
burgerService.deleteBurger(it)
//If the user doesn't have permission to invoke a method,
//we will get AccessDeniedException which we handle and notify the user of the error
} catch (e : Exception){
when (e) {
is AccessDeniedException -> {
model.addAttribute("error", "Only Bob gets to delete burgers!")
logger.info("Security error")
}
else -> logger.error(e.toString(), e)
}
errorThrown = true
}
}
model.addAttribute("burgers", burgerService.allBurgers().toList())
if(!errorThrown){
model.addAttribute("info", "Deleted burgers")
}
return "index"
}
}
You’ll ntoice that the deleteBurgers method looks for AccessDeniedException (which is handled by Koltin’s powerful when block). In our case, we report an error that only Bob get’s to delete burgers.
Putting it all together
Here is a video of a sample web application that demonstrates this code in action.
The code for the example application is available at my GitHub page.
You can also learn more about Spring MVC by referring to the following posts.

















 You will want to have the following dependencies in your package.json file.
You will want to have the following dependencies in your package.json file.