Spotify provides APIs that allow developers to write client applications. This tutorial will demonstrate how to use Node.js to create a simple web application that queries Spotify for information about a particular song. Start by creating a Node.js application with a folder structure that resembles the one shown in this screenshot. You can view a tutorial one how to do this at this link or use your IDE.
 You will want to have the following dependencies in your package.json file.
You will want to have the following dependencies in your package.json file.
{
"name": "spotifynode",
"version": "0.0.0",
"private": true,
"scripts": {
"start": "node ./bin/www"
},
"dependencies": {
"body-parser": "~1.17.1",
"cookie-parser": "~1.4.3",
"debug": "~2.6.3",
"express": "~4.15.2",
"hbs": "~4.0.1",
"morgan": "~1.8.1",
"node-spotify-api": "^1.0.5",
"serve-favicon": "~2.4.2"
}
}
Spotify requires developers to create application keys in order to use their APIs. Follow the guide provided here in order to create a developer account with Spotify. Once you have created an application, you will need to retain the application id and secret.
Start by creating a keys.js file in the routes folder. It should look like the following example.
keys.js
exports.spotifyKeys = {
id: 'Spotify Id Here',
secret: 'Spotify Secret Here'
};
The next thing to do is to write the server side code that handles HTTP GET and POST requests. Here is the code for index.js.
index.js
var express = require('express');
var router = express.Router();
//Import the Spotify API
var Spotify = require('node-spotify-api');
//Import our Keys File
var keys = require('./keys');
//Create a Spotify Client
var spotify = new Spotify(keys.spotifyKeys);
//Store the results of a request to spotify
var results = [];
/* GET home page. */
router.get('/', function (req, res) {
res.render('index', {title: 'Spotify', results: results});
});
router.post('/', function (req, res) {
//Get the type of Query from the User
var type = req.body.param_type;
//Get the query from the user
var query = req.body.param_query;
//Clear out old results
results = [];
//Make a request to Spotify
spotify.search({type: type, query: query})
.then(function (spotRes) {
//Store the artist, song, preview link, and album in the results array
spotRes.tracks.items.forEach(function(ea){
results.push({artist: ea.artists[0].name,
song: ea.name,
preview: ea.external_urls.spotify,
album: ea.album.name});
});
//Render the homepage and return results to the view
res.render('index', {title: 'Spotify', results: results});
})
.catch(function (err) {
console.log(err);
throw err;
});
});
module.exports = router;
This code sets up two handlers for GET and POST requests. More details about how to do this can be found in this post. We begin on line 5 by importing the Spotify API into our script. Then we pull in the keys.js file we created earlier so that we can authenticate with Spotify. The next line creates a spotify object and we pass our creditionals to its constructor.
The next point of interest is the spotify.search found on line 32. The spotify.search function takes in two arguments, type and query. The type argument specifies the type of query and the query is the actual search criteria that we are going to send to the API. The spotify library will make correct rest calls to the Spotify API and it will return a response.
Inside of the body of the promise function, we push some information about the song to the results array so that we can display it to the view. In this case, we are going to grab the artist, song, a preview url, and the song’s album. We then return it to the view for display in a table.
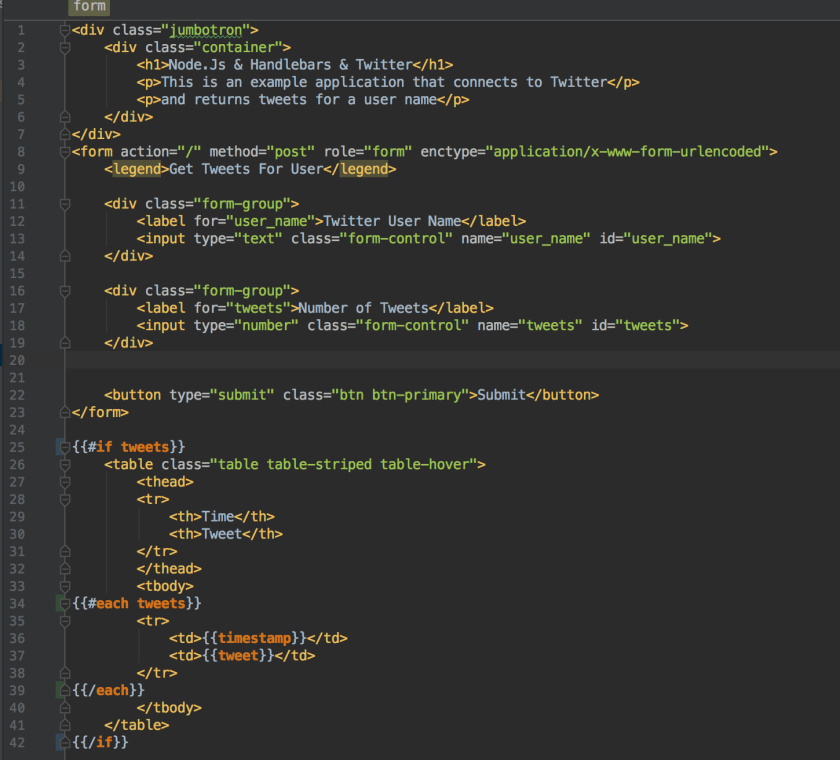
index.hbs
We can use Handlebars to markup a template page that will get returned to the browser from the server.

Conclusion
When run, the application will look like the following screenshots.


You can view the source from my GitHub page at this link.